答、2byte
ES-Jamで確かめてみましょう!
Math.log(31119)/Math.log(2) 14.925508080033552
おや、確か3byteだったはず?という方、それはファイルに書き出す時に使用するUTF-8という変換形式の話です。
8bitのバイナリデータを文字列へと変換するBase122を使ってみましたが、0-127まではUTF-8でも1byteで表現できる有効な文字なので、Base128を作ってみました。
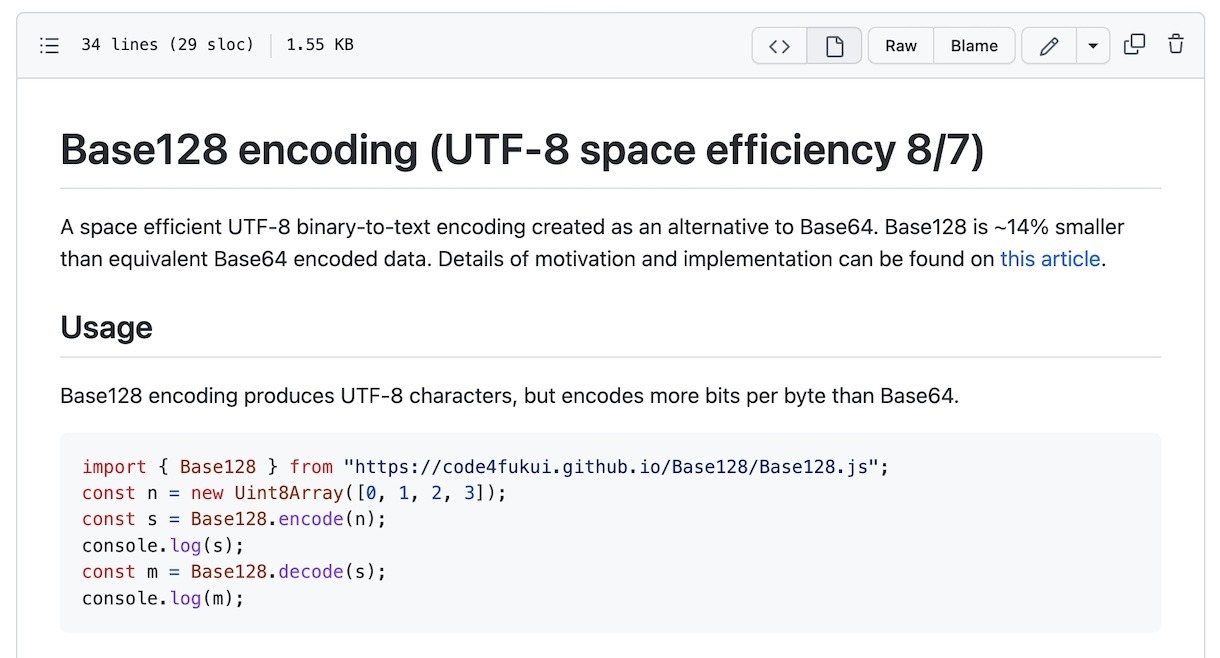
「Base128」
バイナリデータと文字列との相互変換は普通に使えますが、JavaScriptの文字列にしようとすると文字列の始まりの記号、ダブルクォートや、エスケープのための記号、バックスラッシュ、文字列内ではエスケープしないと使えない改行記号(10/13)を変換する encodeJS を使う必要があり、ちょっと容量が増えてしまいます。
改めてBase122の仕組みを読んでみると、上記使えない文字をUTF-8の2byteエンコードを使ってうまく逃がす仕組みになっていました。これだと容量を増やさずに対応できます!スゴイ!ただ、Base122で変換した文字はテキストエディタで表示がおかしくなり、コピペできない文字が含まれてしまっている点が残念です。
そこで、すべての2byteエンコードされる文字を表示してみました。

上位4bit毎に16種類ある2byteエンコードの文字たち。エディタVSCodeにコピーしてみて普通に扱えるセットを調べたところ、2/3/4/5/8が普通に読み書きOK、1/7/10は一部フォントがなかったりするけどコピペOKということで、8種類を使うのが良さそうです。Base122は制御コードみたいのが効いてしまう6を使っていることによる問題でした。
何気なく使っている文字にもいろんな秘密やストーリーがあっておもしろいですね。

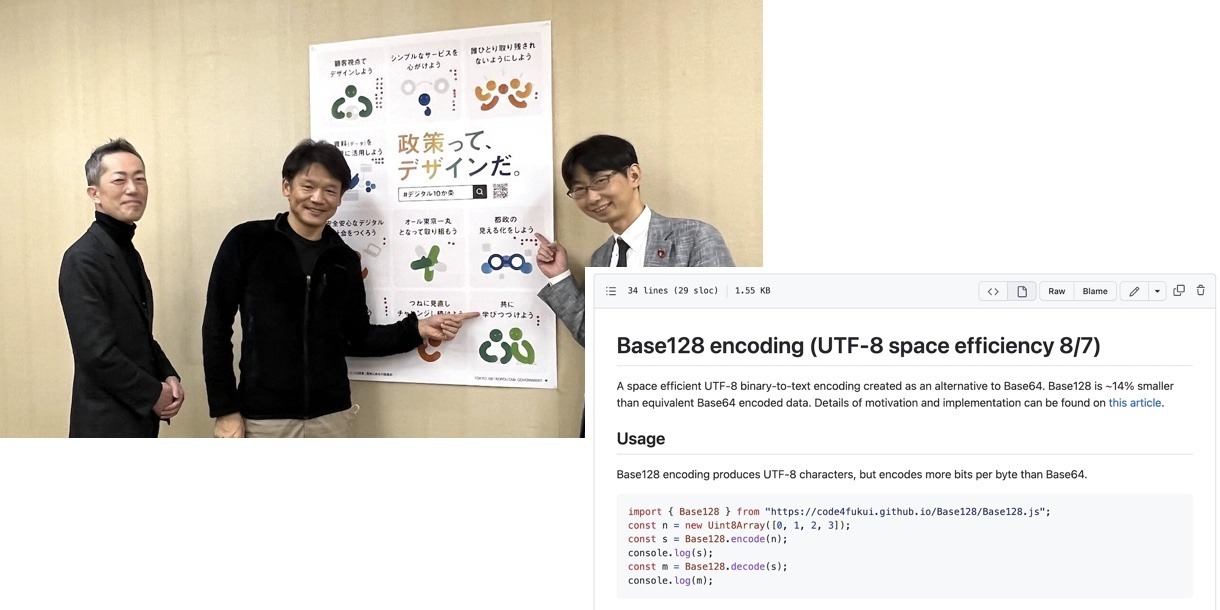
東京都庁、宮坂副知事に初のリアル対面!
東京都が掲げるデジタル10か条「政策って、デザインだ。」に3つシールを貼りました。
私、一番の推しは「#10 ともに学びつづけよう」、続いて「#7 都政の見える化をしよう」「#2 シンプルなサービスを心がけよう」です。



{kind=link}
{kind=link}
{kind=link}