曲を
周波数解析DFTするととんでもない時間がかかることがわかったので、工夫しがいがありそうです。JavaScriptからC言語に書き直し、GPU活用を前に、ひとまずCPUのマルチコアに対応させてみたところ、15倍速にまでなりました。
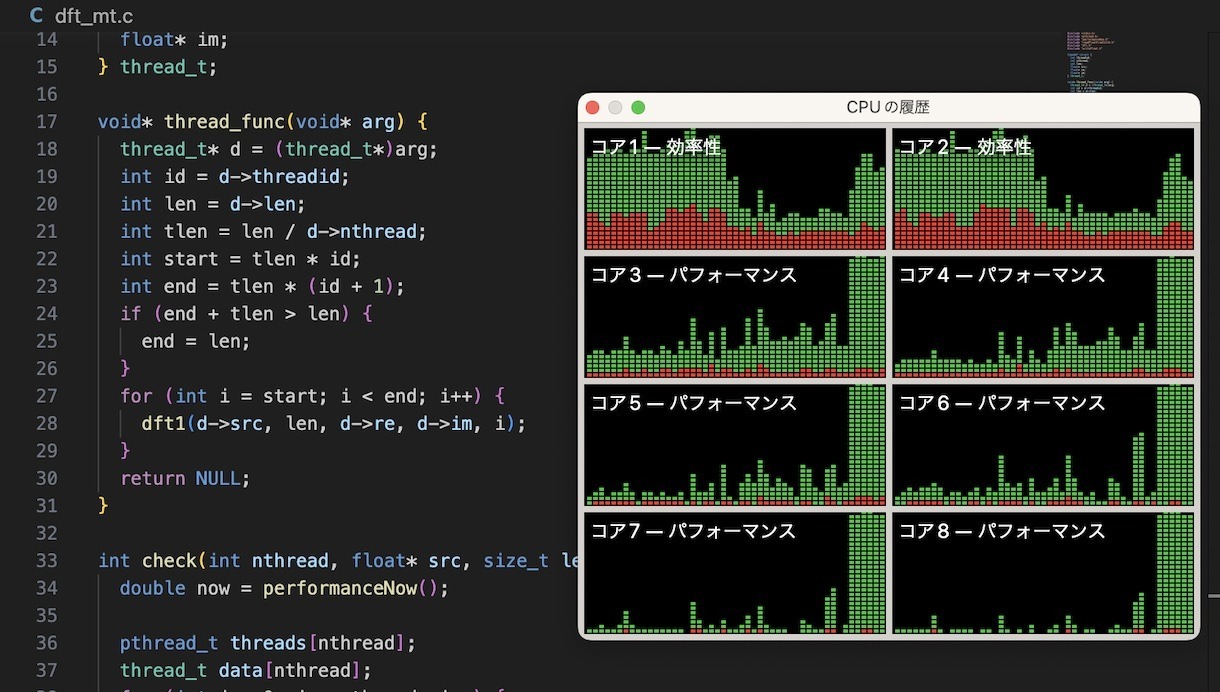
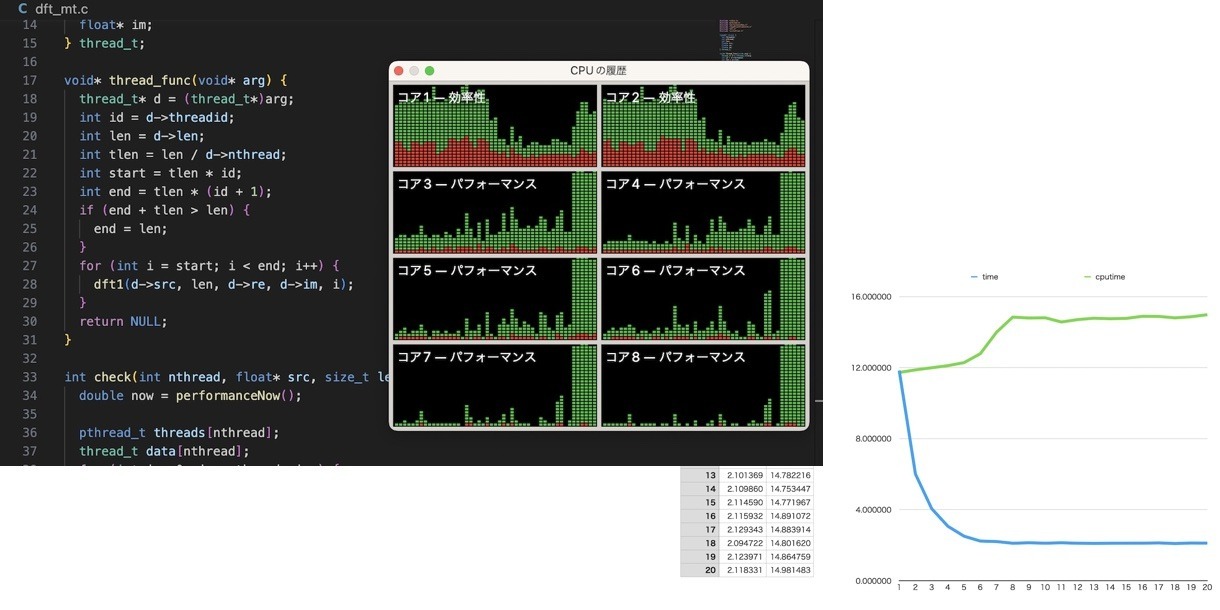
pthreadを使って、M1 Macbook Pro、パフォーマンスコア6つがフル稼働するマルチスレッド対応のDFT!(src on GitHub)
Deno JavaScriptで44100サンプルのDFT(離散フーリエ変換)にかかった時間は、33.18秒。C言語化で11.78秒と3倍速。マルチコア活用で2.25秒と更に5倍速になりました。
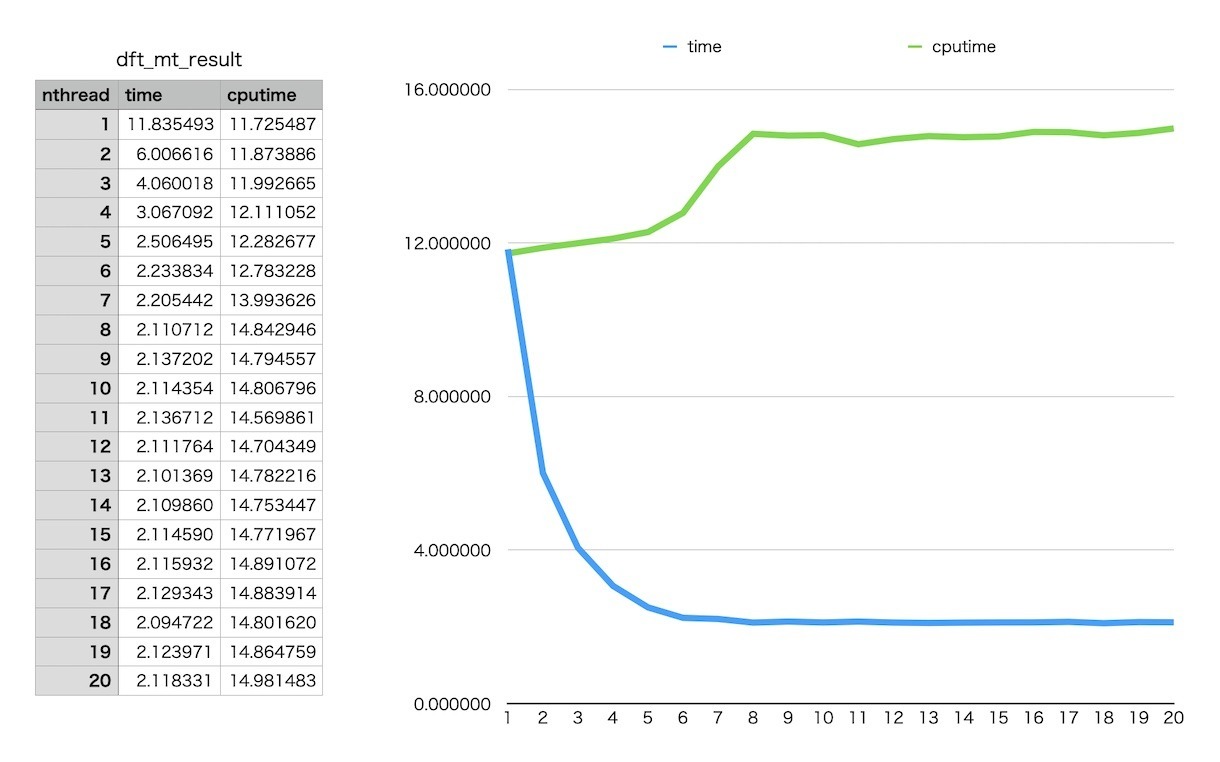
使用するスレッド数を増やしながら実時間とCPU時間を計測してグラフ化したものです。M1 Macbook Proの実コア数6コに対応する6スレッドまで順調に時間は短縮され、以後、CPU時間が若干上昇しますがそのままだいたい安定するようです。コア数が多いCPU、Intel Core i9-13900KS(24コア32スレッド)や、AMD Ryzen Threadripper PRO 5995WX(64コア128スレッド)などでの挙動が気になります。
C言語でのデータの読み書き用にシンプルな単一型の配列バイナリデータ(i32.bin/f32.bin)を採用しました。シングルコアで動作するDFT in C言語はこのように書けます。
#include <stdio.h>
#include "readFloatFromInt16.h"
#include "dft.h"
#include "writeFloat.h"
#include "performanceNow.h"
int main() {
const char* fn = "sekaideichiban.wav-r.i16.bin";
const char* fnre = "sekaideichiban.wav-re.f32.bin";
const char* fnim = "sekaideichiban.wav-im.f32.bin";
size_t len = 0;
float* src = readFloatFromInt16(fn, &len);
if (!src) {
return 1;
}
// DFT
double now = performanceNow();
float* re = (float*)malloc(len * sizeof(float));
float* im = (float*)malloc(len * sizeof(float));
dft(src, len, re, im);
double dt = performanceNow() - now;
printf("time: %f\n", dt); // 44100samples, time: 14.769461
writeFloat(fnre, re, len);
writeFloat(fnim, im, len);
free(re);
free(im);
free(src);
return 0;
}
次は、いよいよCUDA C。GPU活用でどのくらい高速化するでしょう!?
links
- あえて低速、離散フーリエ変換 DFT in Pure JavaScript
- コンピューターをフル活用しよう! 高専DCONテレビ放映とCUDAでライフゲーム
- ブラウザ上でデータを見える化、DataViewer extends HTMLElement



{kind=link}
{kind=link}
{kind=link}