コンピューターのネイティブ言語はマシン語ですが、C言語はそれを手軽に生成してくれます。 今回は、パスワード解読で活躍したGPUプログラミングにC言語を使って挑戦してみましょう!(Mac向け)
マルチコアなCPUや、いろんなメーカーのGPUを統一的に使えるOpenCLを使うと、C言語で簡単に並列プログラミングができます。
MacBookProが対応しているOpenCLのバージョンは1.2。仕様書を読んで、まずは対応デバイスを調べます。
cl_platform_id platform_id[MAX_PLATFORMS]; cl_uint num_platforms; cl_int ret = clGetPlatformIDs(MAX_PLATFORMS, platform_id, &num_platforms); printf("num of platforms: %d\n", num_platforms); // ... つづく詳細は末尾
プラットフォームを取得、デバイスを取得し、デバイスの特性を表示してみると、CPUとGPUが1つずつ得られました。
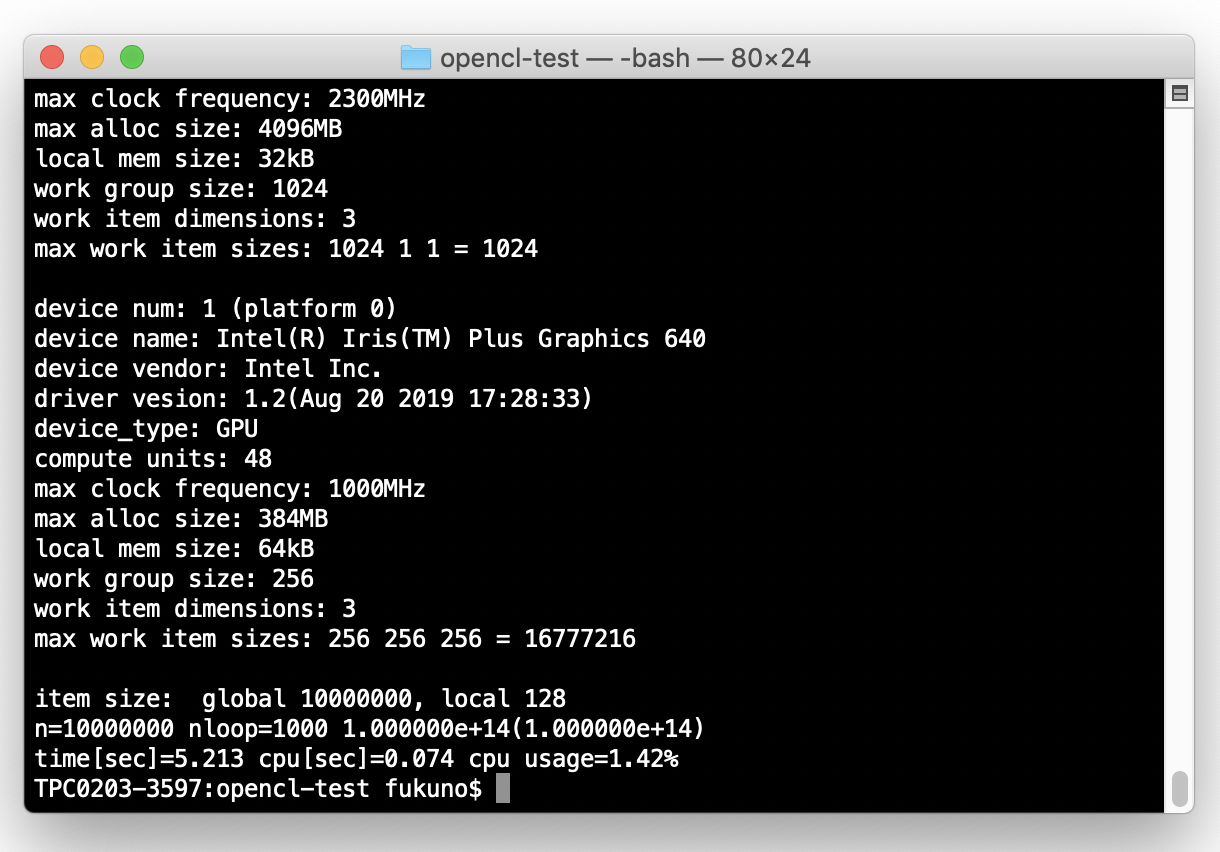
num of platforms: 1 platform num: 0 profile: FULL_PROFILE version: OpenCL 1.2 (Jun 23 2019 21:50:55) name: Apple vendor: Apple extensions: cl_APPLE_SetMemObjectDestructor cl_APPLE_ContextLoggingFunctions cl_APPLE_clut cl_APPLE_query_kernel_names cl_APPLE_gl_sharing cl_khr_gl_event n devices: 2 device num: 0 (platform 0) device name: Intel(R) Core(TM) i5-7360U CPU @ 2.30GHz device vendor: Intel driver vesion: 1.1 device_type: CPU compute units: 4 max clock frequency: 2300MHz max alloc size: 4096MB local mem size: 32kB work group size: 1024 work item dimensions: 3 max work item sizes: 1024 1 1 = 1024 device num: 1 (platform 0) device name: Intel(R) Iris(TM) Plus Graphics 640 device vendor: Intel Inc. driver vesion: 1.2(Aug 20 2019 17:28:33) device_type: GPU compute units: 48 max clock frequency: 1000MHz max alloc size: 384MB local mem size: 64kB work group size: 256 work item dimensions: 3 max work item sizes: 256 256 256 = 16777216
演算処理を行う(compute units)が、CPUに4コ。GPUに48コ。MacBookProには52コの演算器があるんですね!
100万個の配列2つの足し算を計算してみましょう!
for (int i = 0; i < 1000000; i++) { c[i] = a[i] + b[i]; }
ひとまず1000回ループさせて、純粋にCPUのみで計算させて計測して、1.98秒(useopencl=0)
同じ条件で、CPUをデバイスとして使うと、0.57秒(CPU時間は2.6倍とマルチコアが活きてます!)
そしてGPUデバイスを使うと、0.35秒と更に速い!
__kernel void vadd(global const float *a, global const float *b, global float *c, int n) { int i = get_global_id(0); if (i < n) { c[i] = a[i] + b[i]; } }
こちらがOpenCLで使うC言語(vadd.cl として保存)は、再起呼び出しが使えない、可変長引数非対応など一部制限ありますが、ほぼ普通のC言語! 同じパソコン上であっても、独立して動く演算器同士、ネットワーク越しで使うようにつなぐところがおもしろいですね。
意外と簡単に使えることが分かったので、何か実用的なコードづくりにチャレンジしてみたいと思います!
下記、今回のプログラム全文(参考、9.1 OpenCLとは - www.e-em.co.jp/tutorial/chap9.htm)
#include <stdio.h> #include <stdlib.h> #include <time.h> #include <sys/time.h> #include <OpenCL/opencl.h> #define MAX_SOURCE_SIZE 100000 #define MAX_PLATFORMS 10 #define MAX_DEVICES 20 cl_device_id getDeviceCL(cl_device_type type) { cl_device_id res = NULL; cl_platform_id platform_id[MAX_PLATFORMS]; cl_uint num_platforms; cl_int ret = clGetPlatformIDs(MAX_PLATFORMS, platform_id, &num_platforms); printf("num of platforms: %d\n", num_platforms); printf("\n"); size_t len; cl_device_id device_id[MAX_DEVICES]; cl_uint num_devices; cl_uint idx_devices = 0; for (int i = 0; i < num_platforms; i++) { cl_platform_id pid = platform_id[i]; #define MAX_BUFFER 1024 char name[MAX_BUFFER]; len = MAX_BUFFER; printf("platform num: %d\n", i); ret = clGetPlatformInfo(pid, CL_PLATFORM_PROFILE, len, name, &len); // FULL_PROFILE or EMBEDDED_PROFILE printf("profile: %s\n", name); len = MAX_BUFFER; ret = clGetPlatformInfo(pid, CL_PLATFORM_VERSION, len, name, &len); // FULL_PROFILE or EMBEDDED_PROFILE printf("version: %s\n", name); len = MAX_BUFFER; ret = clGetPlatformInfo(pid, CL_PLATFORM_NAME, len, name, &len); // FULL_PROFILE or EMBEDDED_PROFILE printf("name: %s\n", name); len = MAX_BUFFER; ret = clGetPlatformInfo(pid, CL_PLATFORM_VENDOR, len, name, &len); // FULL_PROFILE or EMBEDDED_PROFILE printf("vendor: %s\n", name); len = MAX_BUFFER; ret = clGetPlatformInfo(pid, CL_PLATFORM_EXTENSIONS, len, name, &len); // FULL_PROFILE or EMBEDDED_PROFILE printf("extensions: %s\n", name); ret = clGetDeviceIDs(pid, CL_DEVICE_TYPE_ALL, MAX_DEVICES - idx_devices, device_id, &num_devices); // CL_DEVICE_TYPE_ALL -> 2 (Apple) // ret = clGetDeviceIDs(pid, CL_DEVICE_TYPE_DEFAULT, MAX_DEVICES - idx_devices, device_id, &num_devices); // CL_DEVICE_TYPE_DEFAULT -> 1 printf("n devices: %d\n", num_devices); printf("\n"); for (int j = 0; j < num_devices; j++) { cl_device_id did = device_id[j]; printf("device num: %d (platform %d)\n", j, i); len = MAX_BUFFER; ret = clGetDeviceInfo(did, CL_DEVICE_NAME, len, name, &len); printf("device name: %s\n", name); len = MAX_BUFFER; ret = clGetDeviceInfo(did, CL_DEVICE_VENDOR, len, name, &len); printf("device vendor: %s\n", name); len = MAX_BUFFER; ret = clGetDeviceInfo(did, CL_DRIVER_VERSION, len, name, &len); printf("driver vesion: %s\n", name); cl_device_type device_type; ret = clGetDeviceInfo(did, CL_DEVICE_TYPE, sizeof(device_type), &device_type, &len); if (device_type == CL_DEVICE_TYPE_CPU) printf("device_type: CPU\n"); else if (device_type == CL_DEVICE_TYPE_GPU) printf("device_type: GPU\n"); else if (device_type == CL_DEVICE_TYPE_ACCELERATOR) printf("device_type: ACCELERATOR\n"); else printf("device_type: other %llu\n", device_type); if (device_type == type) { res = did; } cl_uint compute_units; ret = clGetDeviceInfo(did, CL_DEVICE_MAX_COMPUTE_UNITS, sizeof(compute_units), &compute_units, &len); printf("compute units: %u\n", compute_units); // CPU: 4, GPU: 48 cl_uint clock_freq; ret = clGetDeviceInfo(did, CL_DEVICE_MAX_CLOCK_FREQUENCY, sizeof(clock_freq), &clock_freq, &len); printf("max clock frequency: %uMHz\n", clock_freq); // CPU: 2300MHz, GPU: 1000MHz cl_ulong max_alloc_size; ret = clGetDeviceInfo(did, CL_DEVICE_MAX_MEM_ALLOC_SIZE, sizeof(max_alloc_size), &max_alloc_size, &len); printf("max alloc size: %lluMB\n", max_alloc_size / (1024 * 1024)); // CPU: 4096MB, GPU: 384MB cl_ulong local_mem_size; ret = clGetDeviceInfo(did, CL_DEVICE_LOCAL_MEM_SIZE, sizeof(local_mem_size), &local_mem_size, &len); printf("local mem size: %llukB\n", local_mem_size / 1024); // CPU: 32kB, GPU: 64kB size_t work_group_size; ret = clGetDeviceInfo(did, CL_DEVICE_MAX_WORK_GROUP_SIZE, sizeof(work_group_size), &work_group_size, &len); printf("work group size: %zu\n", work_group_size); // CPU: 1024, GPU: 256 cl_uint work_item_dimensions; ret = clGetDeviceInfo(did, CL_DEVICE_MAX_WORK_ITEM_DIMENSIONS, sizeof(work_item_dimensions), &work_item_dimensions, &len); printf("work item dimensions: %u\n", work_item_dimensions); // CPU: 3, GPU: 3 (minimum 3) size_t work_item_sizes[work_item_dimensions]; ret = clGetDeviceInfo(did, CL_DEVICE_MAX_WORK_ITEM_SIZES, sizeof(work_item_sizes), work_item_sizes, &len); printf("max work item sizes: "); // CPU: 1024 1 1 = 1024, GPU: 256 256 256 = 16777216 size_t maxitems = 1; for (int k = 0; k < work_item_dimensions; k++) { printf("%zu ", work_item_sizes[k]); maxitems *= work_item_sizes[k]; } printf("= %zu\n", maxitems); printf("\n"); } } return res; } int main(int argc, char** argv) { //getDeviceCL(NULL); //return 0; const int n = 1 * 1000 * 1000; // 1M float* a = (float*)malloc(n * sizeof(float)); float* b = (float*)malloc(n * sizeof(float)); float* c = (float*)malloc(n * sizeof(float)); for (int i = 0; i < n; i++) { a[i] = i + 1; b[i] = i + 1; c[i] = 0; // a[i] + b[i] } int useopencl = 1; cl_device_type type = CL_DEVICE_TYPE_GPU; //cl_device_type type = CL_DEVICE_TYPE_CPU; cl_device_id device_id = getDeviceCL(type); const int nloop = 1000; // sec -> msec cl_int ret; cl_context context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &ret); cl_command_queue command_queue = clCreateCommandQueue(context, device_id, 0, &ret); // load program for GPU FILE* fp = fopen("vadd.cl", "r"); if (!fp) { fprintf(stderr, "kernel source open error\n"); exit(1); } char* source_str = (char*)malloc(MAX_SOURCE_SIZE * sizeof(char)); size_t source_size = fread(source_str, 1, MAX_SOURCE_SIZE, fp); fclose(fp); cl_program program = clCreateProgramWithSource(context, 1, (const char**)&source_str, (const size_t*)&source_size, &ret); if (ret != CL_SUCCESS) { fprintf(stderr, "clCreateProgramWithSource() error\n"); exit(1); } free(source_str); if (clBuildProgram(program, 1, &device_id, NULL, NULL, NULL) != CL_SUCCESS) { fprintf(stderr, "clBuildProgram() error\n"); exit(1); } cl_kernel kernel = clCreateKernel(program, "vadd", &ret); if (ret != CL_SUCCESS) { fprintf(stderr, "clCreateKernel() error\n"); exit(1); } // memory cl_mem d_a = clCreateBuffer(context, CL_MEM_READ_WRITE, n * sizeof(float), NULL, &ret); cl_mem d_b = clCreateBuffer(context, CL_MEM_READ_WRITE, n * sizeof(float), NULL, &ret); cl_mem d_c = clCreateBuffer(context, CL_MEM_READ_WRITE, n * sizeof(float), NULL, &ret); // host to device clEnqueueWriteBuffer(command_queue, d_a, CL_TRUE, 0, n * sizeof(float), a, 0, NULL, NULL); clEnqueueWriteBuffer(command_queue, d_b, CL_TRUE, 0, n * sizeof(float), b, 0, NULL, NULL); // args for program clSetKernelArg(kernel, 0, sizeof(cl_mem), (void*)&d_a); clSetKernelArg(kernel, 1, sizeof(cl_mem), (void*)&d_b); clSetKernelArg(kernel, 2, sizeof(cl_mem), (void*)&d_c); clSetKernelArg(kernel, 3, sizeof(int), (void*)&n); // work item size_t local_item_size = 128; // limit on MacBookPro: <=128(CPU) CL_INVALID_WORK_GROUP_SIZE(-54), <=256(GPU) CL_INVALID_WORK_ITEM_SIZE(-55) size_t global_item_size = ((n + local_item_size - 1) / local_item_size) * local_item_size; printf("item size: global %zu, local %zu\n", global_item_size, local_item_size); /// timer clock_t startClock = clock(); struct timeval startTime; gettimeofday(&startTime, NULL); // run if (useopencl) { for (int loop = 0; loop < nloop; loop++) { ret = clEnqueueNDRangeKernel(command_queue, kernel, 1, NULL, &global_item_size, &local_item_size, 0, NULL, NULL); if (ret != CL_SUCCESS) { fprintf(stderr, "clEnqueueNDRangeKernel() error %d\n", ret); exit(1); } } // device to host clEnqueueReadBuffer(command_queue, d_c, CL_TRUE, 0, n * sizeof(float), c, 0, NULL, NULL); } else { for (int loop = 0; loop < nloop; loop++) { for (int i = 0; i < n; i++) { c[i] = a[i] + b[i]; } } } // timer clock_t endClock = clock(); double cpu = (double)(endClock - startClock) / CLOCKS_PER_SEC; struct timeval endTime; gettimeofday(&endTime, NULL); time_t diffsec = difftime(endTime.tv_sec, startTime.tv_sec); suseconds_t diffsub = endTime.tv_usec - startTime.tv_usec; double time = diffsec + diffsub * 1e-6; // output double sum = 0; for (int i = 0; i < n; i++) { //printf("%f ", c[i]); sum += c[i]; } double exact = n * (n + 1.0); printf("n=%d nloop=%d %e(%.6e)\n", n, nloop, sum, exact); printf("time[sec]=%.3f cpu[sec]=%.3f cpu usage=%.2f%%\n", time, cpu, cpu / time * 100); // release clFlush(command_queue); clFinish(command_queue); clReleaseMemObject(d_a); clReleaseMemObject(d_b); clReleaseMemObject(d_c); clReleaseKernel(kernel); clReleaseProgram(program); clReleaseCommandQueue(command_queue); clReleaseContext(context); // free free(a); free(b); free(c); return 0; }
上記 test.c として保存して、下記コマンドでコンパイル&実行!
$ gcc test.c -framework OpenCL $ ./a.out
links
- Khronos OpenCL Registry - The Khronos Group Inc
- 9.1 OpenCLとは - www.e-em.co.jp/tutorial/chap9.htm
- MacのGPUでも700倍速! パスワード20文字時代の盾と矛 / さくらクラウドで分散探査する方法
- パスワード付きZIPファイルの有効性検証! Go言語を使ったマルチコア対応パスワードチャレンジプログラム



{kind=link}
{kind=link}
{kind=link}