
開発開始!
ウェブサイトの入口といえば index.html ですが、Googleなどのサーチエンジンなど、プログラムによる自動閲覧(クローラー)のための入口は robots.txt。AllowとDisallowで辿っていいところとだめなところ、サイトマップ(sitemap.xml)が記述されています。 「サイトマップの作成と送信 - Search Console ヘルプ」によると、ひとつのサイトマップに50MB or 5万URLまで設定できるとのこと(オーバーする場合は sitemapタグ を使いましょう、500コまで)
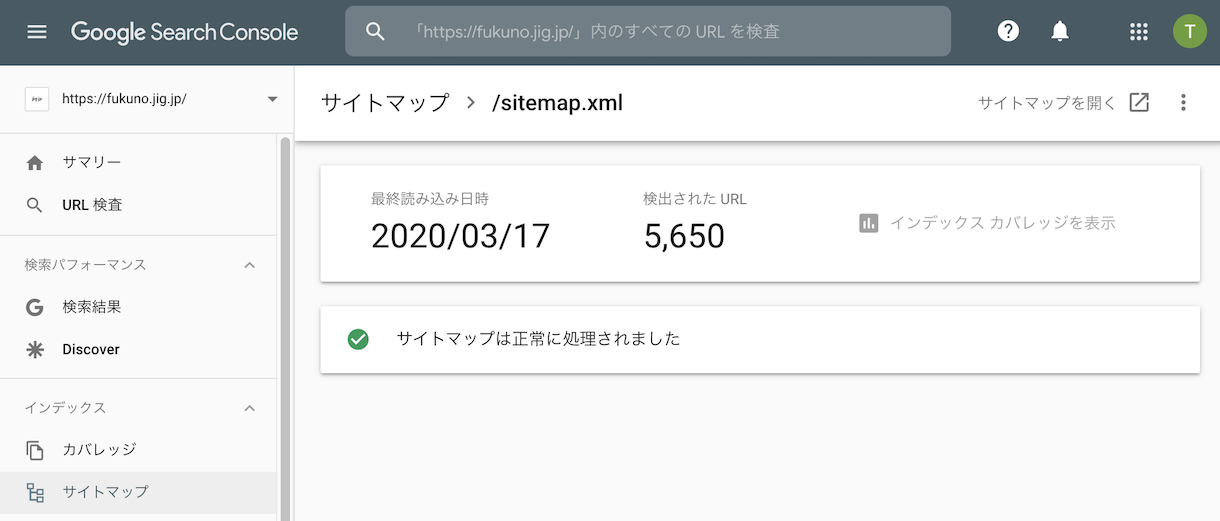
長らく放置してしまっていた一日一創 robots.txt を更新!オープンデータな当サイト、もちろん全件 Allow です。今回サイトマップ(sitemap.xml)も追加!
2012年の一日一創はまだいれてませんが、アプリなど含めて、5,650ページあったようです。
人間のためのHTMLという言語は、プログラムでは理解しづらいので、統一されたボキャブラリー(語彙)を HTML5 の itemscope 属性を使って、意味を明示することができます。
例えば、映画を紹介するHTMLはこんな感じ。(参考、Getting Started - schema.org)
<div itemscope itemtype="http://schema.org/Movie"> <h1 itemprop="name">AKIRA</h1> <div>監督: <span itemprop="director">大友克洋</span></div> <div>ジャンル: <span itemprop="genre">SFアニメ</span></div> <div>出典: <a itemporp="url" href="https://eiga.com/movie/34459/">AKIRA : 作品情報 - 映画.com</a></div> </div>
itemscope と itemtype で、そのデータが何なのかを明示(この場合、映画 Movie)し、itempropを使って監督(director)、ジャンル(genre)、出典URL(url)を属性として明示しています。 「AKIRA : 作品情報 - 映画.com」のサイトでも、itemscope / itemtype / itemprop が使われているので、ソースを見てみましょう。
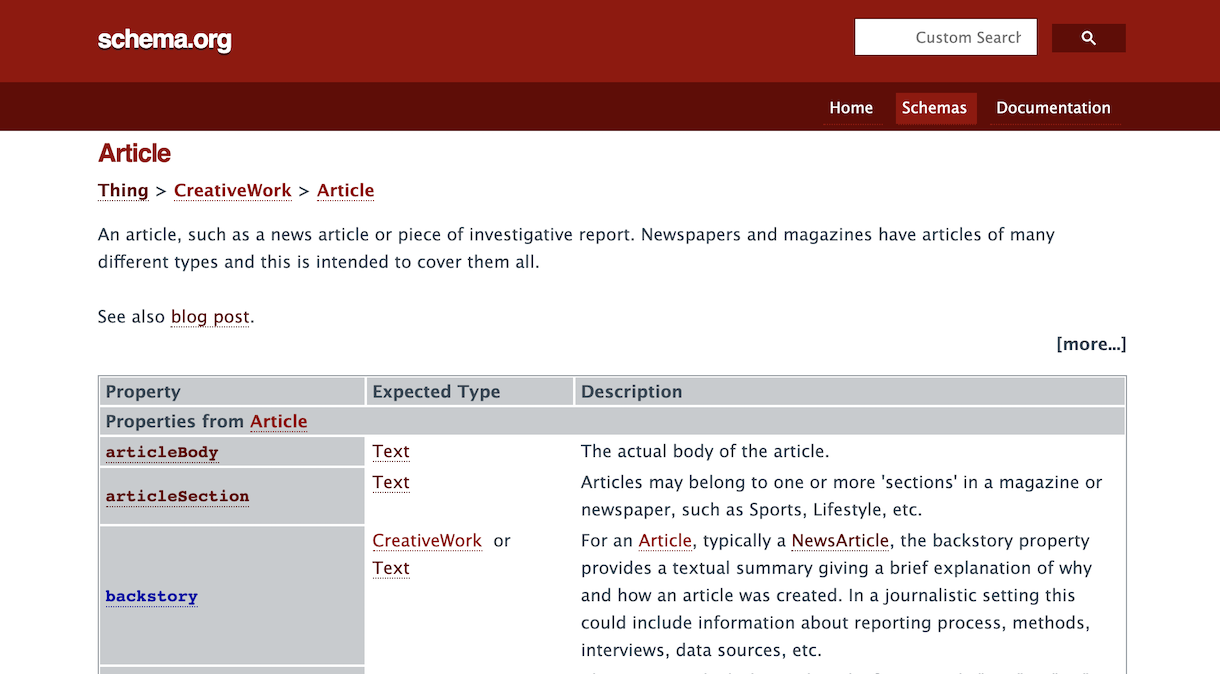
ブログ「一日一創」の記事は Article(記事) を使ってマークアップしました。
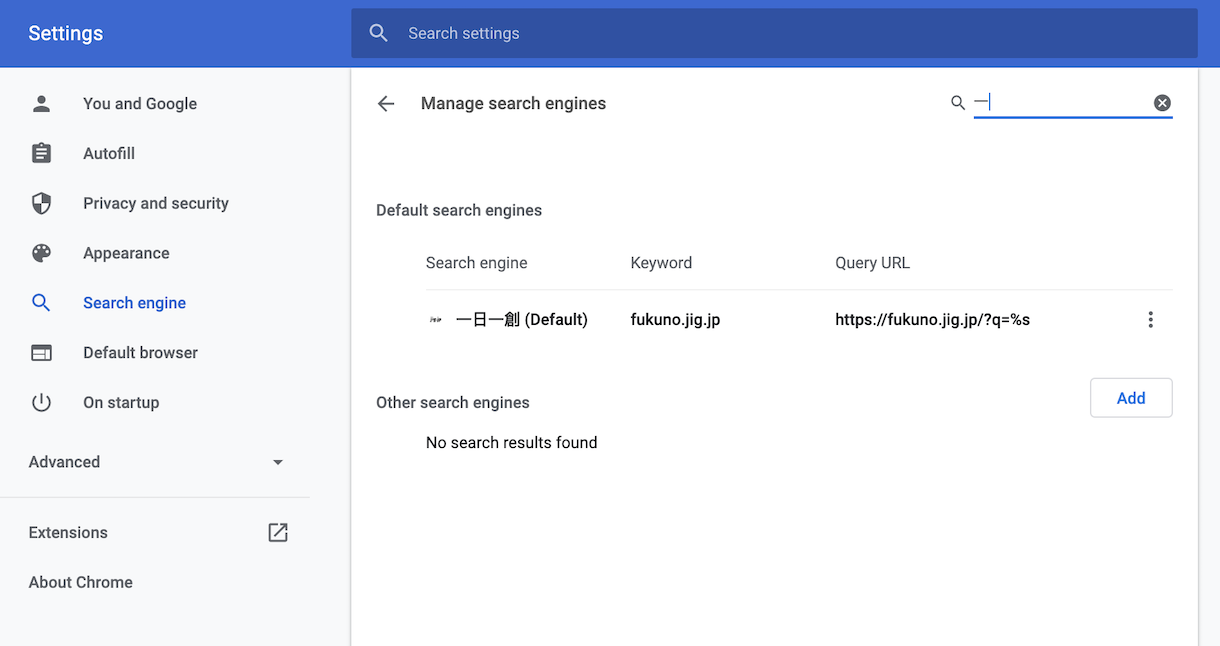
サイト検索が使えることも opensearch を使って、明示。ブラウザによってデフォルトの検索エンジンにしたり、いろいろと便利にしてくれます。検索の利便性も上げないと!
マシンリーダブルなウェブは、エンジニアフレンドリー!
tags
- 所要時間: 3分
- ジャンル: 3分でわかるTech記事



{kind=link}
{kind=link}
{kind=link}