100円のCPUでも1秒間5,000万回計算してくれますが、4K動画に必要な2500万コのLED制御、1コ1計算だとしても1秒間に2コマの紙芝居にしかなりません。 滑らかで美しい映像を計算するためには高速化が欠かせません。
計算で作る美しい映像例「ライフゲーム」、IchigoJamでも「Kubotaさんのライフゲーム - IchigoJam-FAN」にて、高速化チャレンジ中。 100円CPU、Arm Cortex-M0では、足し算、引き算、掛け算と比較して、割り算が150倍遅いことを「IchigoJamマシン語入門」で確認しました。では、普通のPCではどうでしょうか?
MacやWindowsは、Intel/AMDのx64アーキテクチャーが大半です。Intelの資料によると、レイテンシー(ざっくり実行してから結果がでるまでの時間)で、掛け算(MUL)は足し算(ADD)の3倍、割り算(DIV)は足し算の80倍〜90倍ほどかかることがわかります。
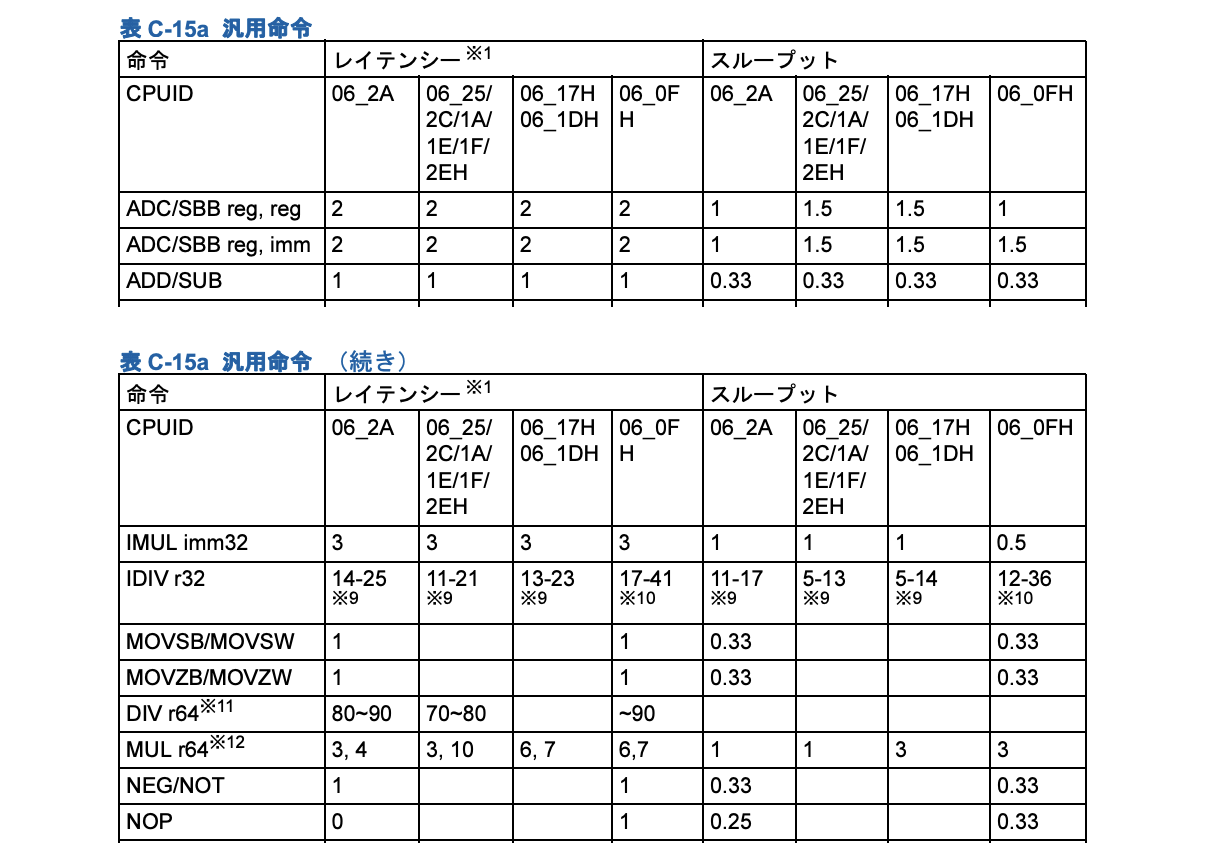
「インテル ® 64 アーキテクチャーおよび IA-32 アーキテクチャー最適化リファレンス・マニュアル」
プログラミング言語、コンパイラーを作る人には必見のこの資料、日本語でここまで用意されているのはスゴイ!
ちなみに、ハードウェア除算命令がある Arm Cortex-M3 での掛け算は足し算と変わらず1クロック、除算はその2〜12倍です。(18.2. プロセッサ命令のタイミング - ARM Information Center)
どんな環境でもループ内の割り算は少なくするのが得策です。ループ外にもって行けないか、ビットシフトや掛け算で代用できないか検討しましょう。32で割る整数計算は、2進法のビット演算で5bit右にシフトするのと一緒で、速度はどのアーキテクチャーでも1クロックになるのでとても有効です。
掛け算の使用はアーキテクチャーで判断が分かれます。IchigoJamやスマホなど、Armアーキテクチャーでは掛け算が足し算と同様に高速なので、カジュアルに使えますが、PC向けの場合多少命令が増えても、事前計算や、足し算ビット演算などでの代用が有効そう。
IchigoJamでのライフゲーム、1更新が16秒から14.5秒に短縮されたとのこと!Cortex-M0は、構造がシンプルなので速度計算が簡単で、遅い分、効果が体感で分かるのが楽しいです。
ループ内を軽くする手段の一つ、並列化。Intel/AMDのx64には512bitのSIMD命令、AVX-512という512bit(8bit x 32コ)まとめて計算する命令があります。
zmm0〜zmm31という512bitレジスタを使った計算ができるとのことでしたが、残念ながら今使っているMacBookProではちょっと古くて非対応。
AVX2の256bit(ymm0〜ymm15)で足し算(vpaddb = 1クロック)させてみました。(src for Mac on GitHub)
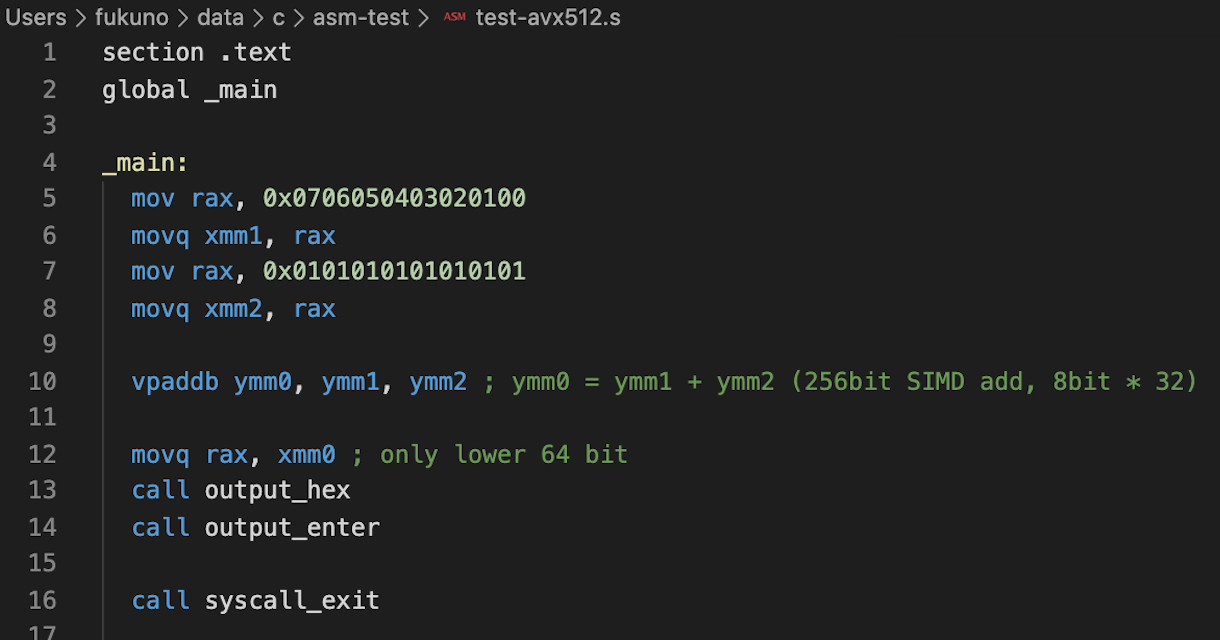
せっかくなら持てる力、フルパワー使いたいですね!もっと長いビット長が計算できるRISC-Vのベクトル拡張も楽しみです。
GPUやFPGAなど、高速化のための様々な技術、必要に応じて楽しく使っていきましょう!
2020-06-29 追記、すみません!執筆時、10倍、66倍〜80倍と記述していたのは異なるCPUIDでの比較をしていました(図、ご指摘ありがとうございます! @57tggx さん)。
現行のアーキテクチャーを調べて、比較表を作ってみたところ、下記のようになりました。2008年のNehalemでは、掛け算で10倍、割り算で70-80倍でした。2015年のSkylakeで少し遅くなっています。Ice LakeはSkylakeがベースとの記述があるので、この部分は変わっていないのではないかと思います。
links
- サイズを取るかスピードを取るか、割り算のアルゴリズムとマシン語実装 / IchigoJamではじめるArmマシン語その14
- ハンドアセンブルで高速計算! RISC-V、RV32ICエミュレーターのC言語実装
- MacのGPUでも700倍速! パスワード20文字時代の盾と矛 / さくらクラウドで分散探査する方法
- Macで開発、FPGAで作る4bit学習用CPU「GMC-4」 - Parallels x Ubuntu x Quartus x Verilog



{kind=link}
{kind=link}
{kind=link}
{kind=link}