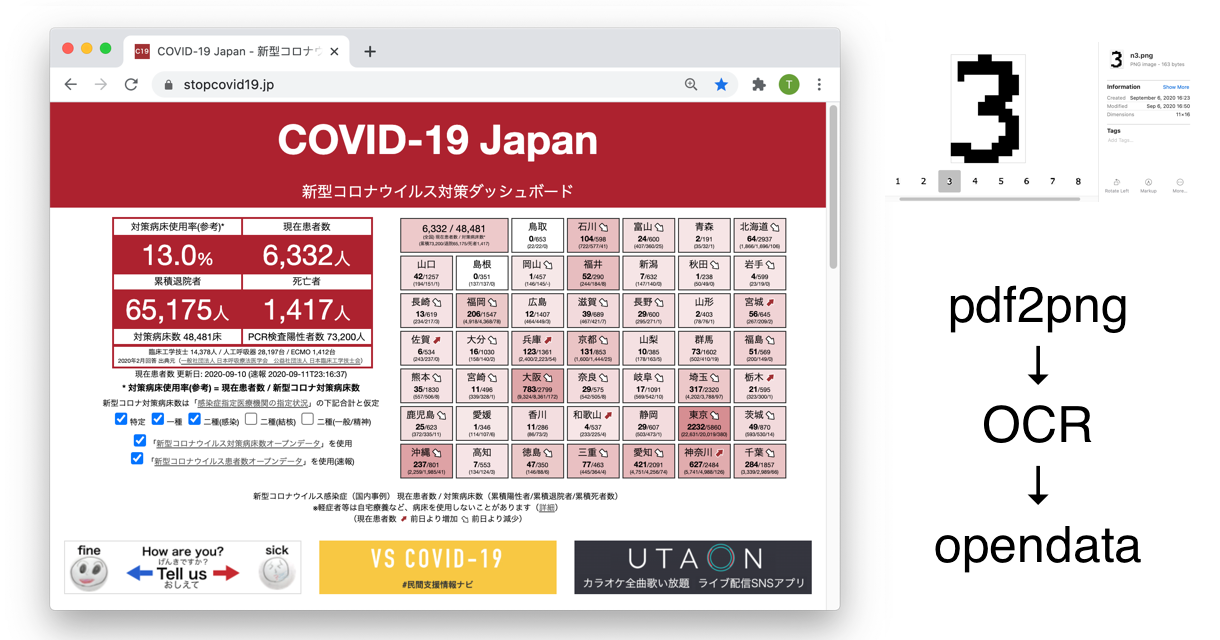
「COVID-19 JAPAN - 都道府県別 新型コロナウイルス陽性患者数)」
先日、該当ファイルが急にベクトル画像PDFとなって変換エラー。 JUST PDF4の助けを借りて、2日間を乗り切り、その後は再びテキストPDFに戻って事なきを得た。 ただ、もう発生しないとは限らないので、自動化できるツールを用意しておいた。
変換アルゴリズム
1. PDFファイルを画像化(pdf2png)
2. 画像から特定位置の数字画像を数値化
3. CSVファイルとして出力
1. macOSでは、PDF操作用のクラスがあって変換は簡単にできる。 発見した、Objective-Cによる実装、pdf2png.m by typester をCatalinaでもコンパイルできるよう調整、背景を白塗りつぶし、解像度を上げて保存するように改良した。(pdf2png.m on GitHub Gist)
gcc --std=c99 -Wall -g -o pdf2png pdf2png.m -framework Cocoa
2. まずは文字画像を抜き出す。白かどうかを縦横でチェックし、1文字を抽出。0から9までの数を画像ファイルとして手動で集める。 続いて、数字が書かれているる領域を特定。レイアウトは固定のようなので、必要箇所を決め打ちで走査することにし、前述と同様の手順で抜き出した画像と0から9までの画像の一点ずつを単純に差分をとった合計値を計算し、一番差分が少ないものがその数値だと判定するプログラムをつくる。 手書き文字認識の場合、ニューラルネットワークなどを使うといいが、元のフォントが同じなので、安定性は高いはず。(src on GitHub)
3. 抽出したデータで合計値で検算。簡単なエラーチェックにもなって、安心度アップ。
罫線を自動的に認識させると、より汎用的に使えていいかもしれない。OCRを使わないで済む、CSVオープンデータとしてもらえるのが一番だが、オープンデータであればなんとかできる武器は多いに越したことはない。
困ったときにどうにかできるスキルを磨くのにオススメ、中止になった高専プロコン競技部門を勝手につくるオープンソース企画「囲みます」。 強いAIアルゴリズムを考えて、実装して、楽しく対戦して遊んでいる内に実装力つきますよ!
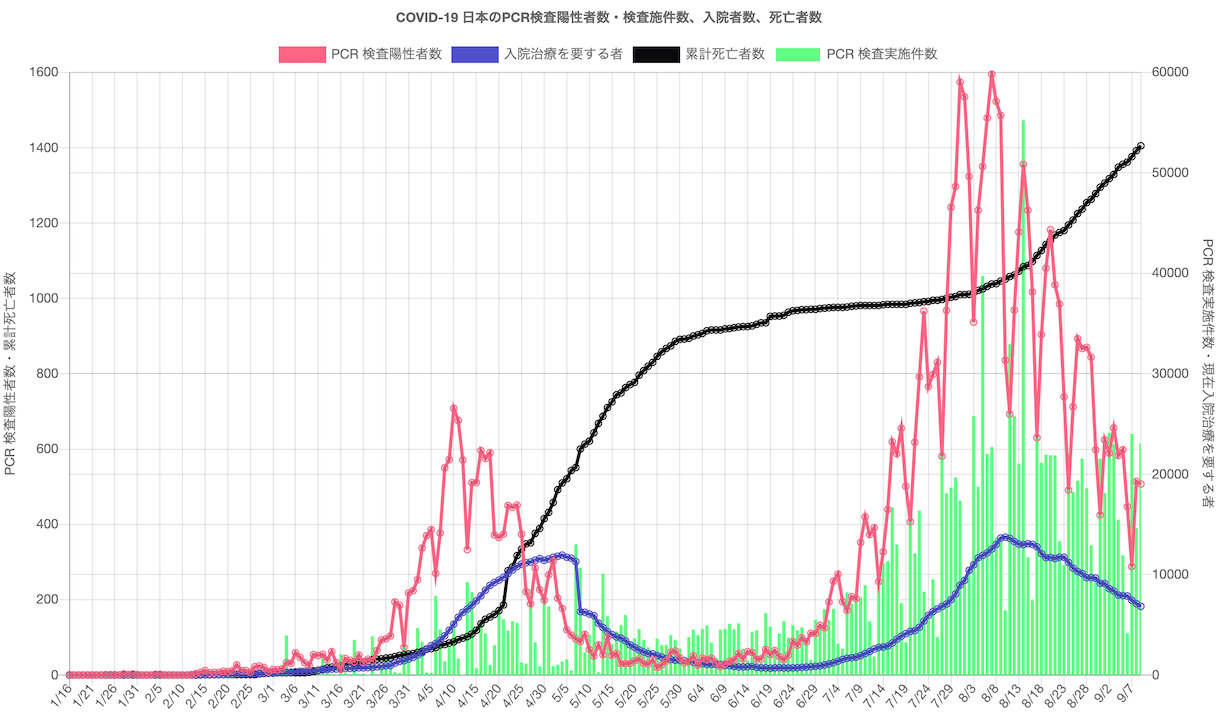
「データ出典:オープンデータ|厚生労働省(新型コロナウイルス感染症について)」
第三波はどうなるか!?



{kind=link}
{kind=link}
{kind=link}