障害の理解と、課題に対するアイデアソン、ハッカソンなど、継続的なものづくりがポイントです。
Code for Fuchu連携で、COTTONさくらんぼの岩間由里子さんからも情報提供。
筋ジストロフィーで手足に障害があり、2cm四方を範囲としたスライドと押し込み動作だけで使えるスマホを熱望。オープンデータ化と、使う人に合わせたアプリの横展開、必須ですね!
実際に、指一本でスマホ操作にチャレンジしましたが、指を画面から離せないという条件は厳しく、通常操作が無理でした。
調べるとiPhoneの3Dタッチなど、タッチパネルの力のかけ具合は、mouseforce系のAPIをブラウザ上で取得もできるので、いろいろ実験してみたいと思います。
「iOS9で追加されたForceTouch(3DTouch)をJavaScriptで操作してみる | WebDesign Dackel」
また、日本筋ジストロフィー協会でも「ワンキーマウス試作報告」の事例が掲載されていました。

主催、Code for Japan コーポレートフェローシップ、鯖江市臨時職員三ツ山さん(富士通)
アイマスクをつけてアイデアソン。
目に優しく、耳が研���澄まされ、隣のテーブルの会話もよく聞こえちゃいます。
声でジャンケンして、ファシリテーターを決め、アイデアのディスカッションスタート。
まとめるための紙が使えない点が心配でしたが、みんな条件が同じなので、ひとつひとつ整理して進める意識を共有できて意外といい感じです。

つづいて、障害体験。高齢者シミュレーショングッズを借りて、重りをつけたり、膝の動きを制限する器具を付けて歩き回ってみます。
普段の何でもない生活の難易度がアップするので、刺激が欲しい人にもオススメです!

制限された視野をシミュレートするメガネ。

アイマスクをして、杖をもって点字ブロックを辿るチャレンジ。
センサーやGPSをつけた、IoT白杖をお互いつくって、難易度高いコースで対戦などできると楽しそう。

「Webアプリはじめのいっぽ」でHTMLの基本を覚えて、ハッカソンタイム!
WebRTCを使って、世界中どこからでもサポートできる!(featuring SkyWay)
「スカイボイス」

アイマスクとスマホを装備をして自販機での買い物チャレンジ!

先のアイデアソンで登場した「おたすけパンダ」と「Pくん」の実現、AIチャットによる市役所窓口デモ。
「おたすけパンダPくん」
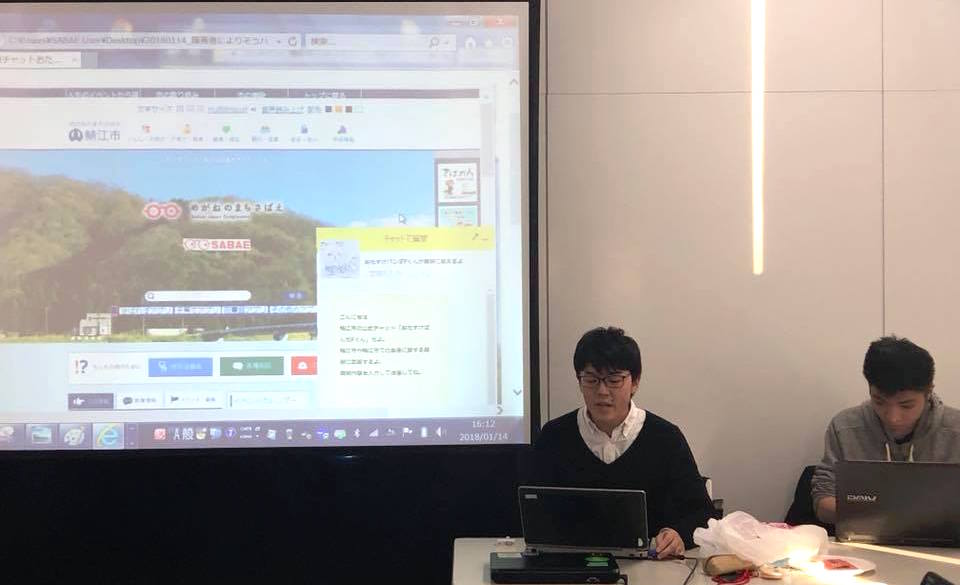
鯖江市も公開した、給付金オープンデータによる質問応答機能のデモに加え、音声認識と音声合成を使った窓口も実験。
Google Cloud Speech APIを使うと、高精度な音声認識が簡単に実現できます。
1回(15秒)$0.006(=約0.6円)の有料APIですが、1ヶ月60分、最大240回まで無料で使えます。
APIKEYを取得してみましょう。
とりあえず、音声認識とそれに対する回答するシンプルなデモスクリプト aichat.sh for Mac を作成。
(参考、GoogleのSpeech APIを使ってみた - Qiita)
read -p "hit to start" rec --encoding signed-integer --bits 16 --channels 1 --rate 16000 test.wav ffmpeg -y -i test.wav -ar 16000 test.flac echo -e "{\n 'config':{\n 'encoding':'FLAC',\n 'sampleRate':16000,\n 'languageCode':'ja-JP' \n }, \n 'audio': { \n 'content': '`base64 test.flac `' \n } \n }\n" > sync-request.json curl -X POST -H "Accept: application/json" -H "Content-type: application/json" --data @sync-request.json https://speech.googleapis.com/v1beta1/speech:syncrecognize?key=【APIKEY】 > response.json python3 talkresponse.py ./aichat.sh
* rec は、音声操作ツール sox に含まれます
音声認識結果 response.json から、認識した文字列を読み取り、会話するプログラム talkresponse.py for Python3 がこちら。(Open JTalkをimportしてます)
# coding: utf-8 import jtalk import sys import time import json import urllib.request cnv = { "おはよう" : "おはようございます", "今日の天気は" : "たぶん晴れです", "こんにちは" : "こんにちは", "がんばって" : "がんばる!", "かわいい" : "ありがとう", "ありがとう" : "どういたしまして", "免許返納について教えて" : "つつじバスとか確かお得に乗れるよ。詳しくは鯖江市のサイトを見てね", "読み書きが苦手です" : "読み書きの苦手なお子さんの相談講座が、3月11日にありますよ", "プログラミングを勉強したい" : "イチゴジャムがオススメ!ハナ道場へどうぞ", "うまいもの" : "サバエドッグ", "甘いもの" : "冬のかんみといえば、みずようかん!", "鯖江のうまいもの" : "サバエドッグ", "鯖江の美味しいもの" : "サバエドッグ", # "鯖江商店街、ミート・アンド・デリカささきの、サバエドッグ", "鯖江と言えば" : "メガネ!鯖江駅から徒歩10分、めがね会館へどうぞ!", "鯖江市長の名前は何ですか" : "まきのひゃくおです", # 写真でるといい } def a(): with open('response.json', 'r') as f: data = json.load(f) s = data['results'][0]['alternatives'][0]['transcript'] print(s) # 認識できた文をとりあえず表示 for t in cnv: if t == s: jtalk.jtalk(cnv[t]) # 対応する回答があった! return if s.endswith("て"): jtalk.jtalk("わかった!") # todo ちゃんとやってあげるプログラムを書く return jtalk.jtalk("ごめんなさい!よくわからないから勉強しておくね。") # todo わからなかった質問を記録しておき、しかるべき人に通知するプログラムを書く a()
とりあえず、いい加減なAIができました!
オープンデータを学習させて、文脈に応じた回答を考えるなど、おもしろそうです。
音声認識&音声合成部分を切り出したデバイスにするために必要なメモリ量は、16kHz、16bit、15秒で約469KB。
ちょっとメモリ大きめのマイコンがあれば、いけそうですね!
ハッカソンの様子が公開されました!



{kind=link}
{kind=link}
{kind=link}