 データを文字化するエンコーディング。16384コの漢字を使ったエンコーディング「
データを文字化するエンコーディング。16384コの漢字を使ったエンコーディング「ありました、点字です!
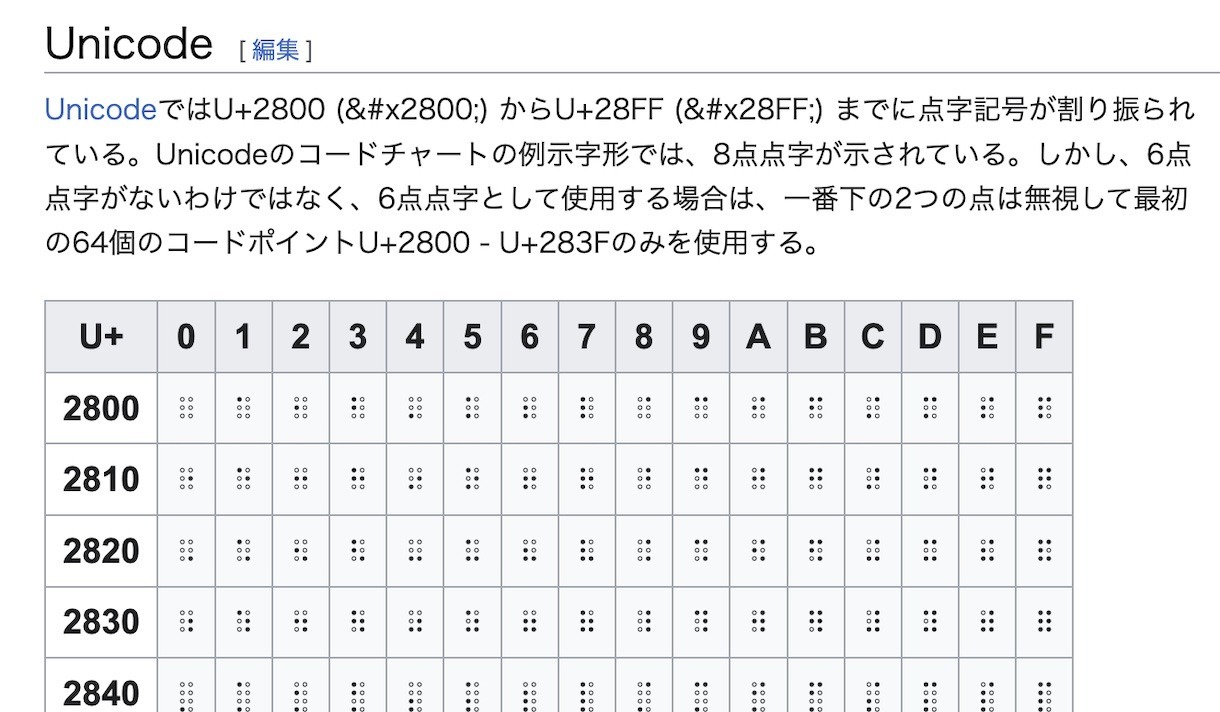
「点字#Unicode - Wikipedia」
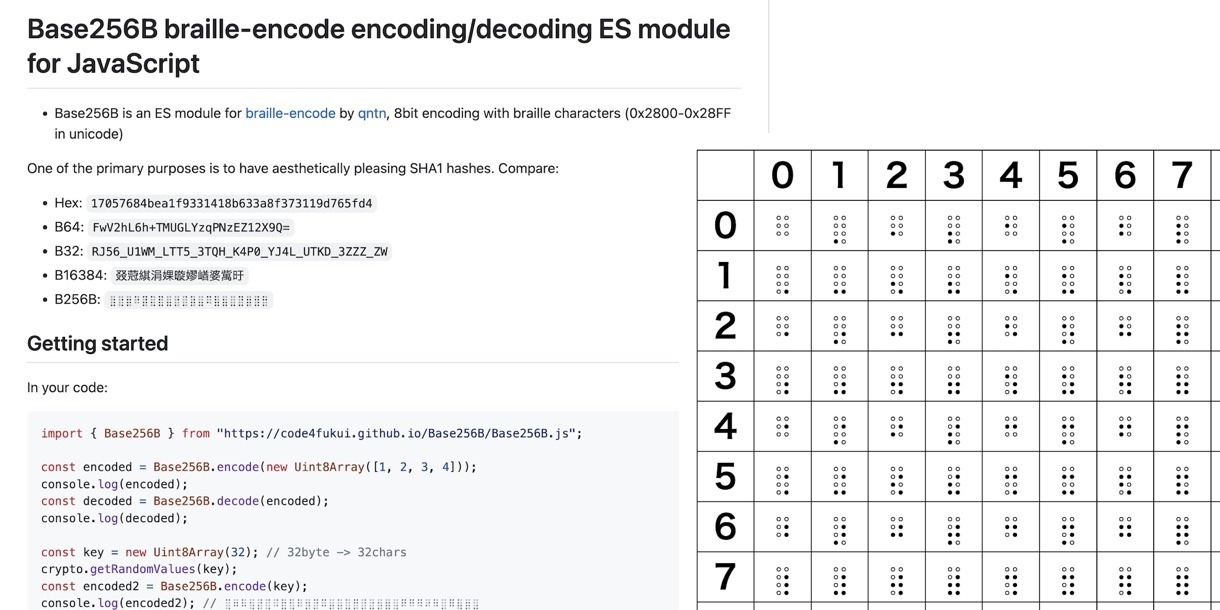
一般的な点字は6点ですが、ユニコードには8点を含むちょうど256パターンの定義があります。U+2800〜U+28FF。
この点字を使ったエンコーディング、すでにqntm氏による実装「braille-encode」がありました。上位4ビットが左、下位4bitを右、それぞれ下が下位ビットになるように2進法で読めるよう、いい具合に並び替えてエンコーディングされています。
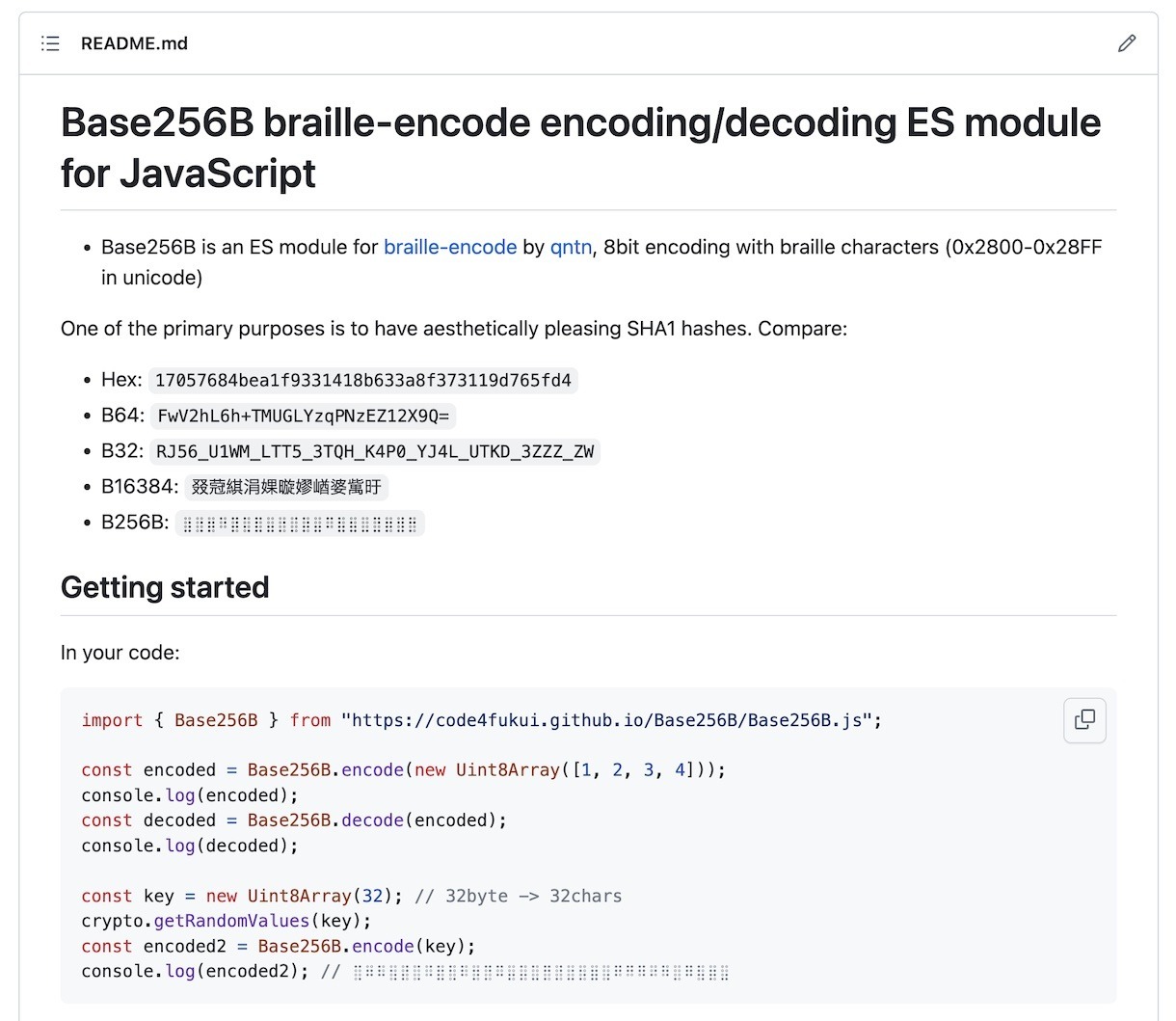
「Base256B braille-encode」
この仕様を踏襲し、Base256Bと名付けてESモジュール化。
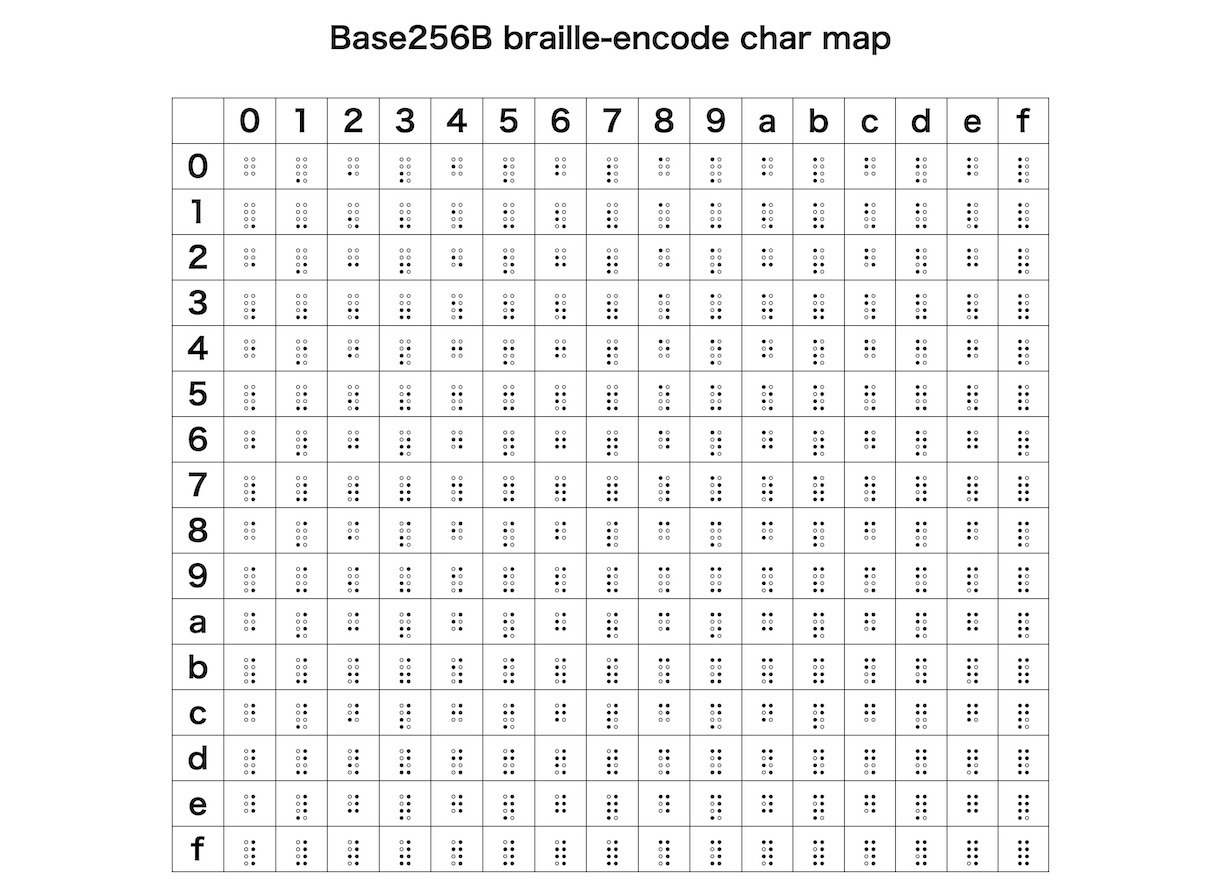
「Base256B braille-encode char map」
一覧表を表示するデモアプリもつくってみました。
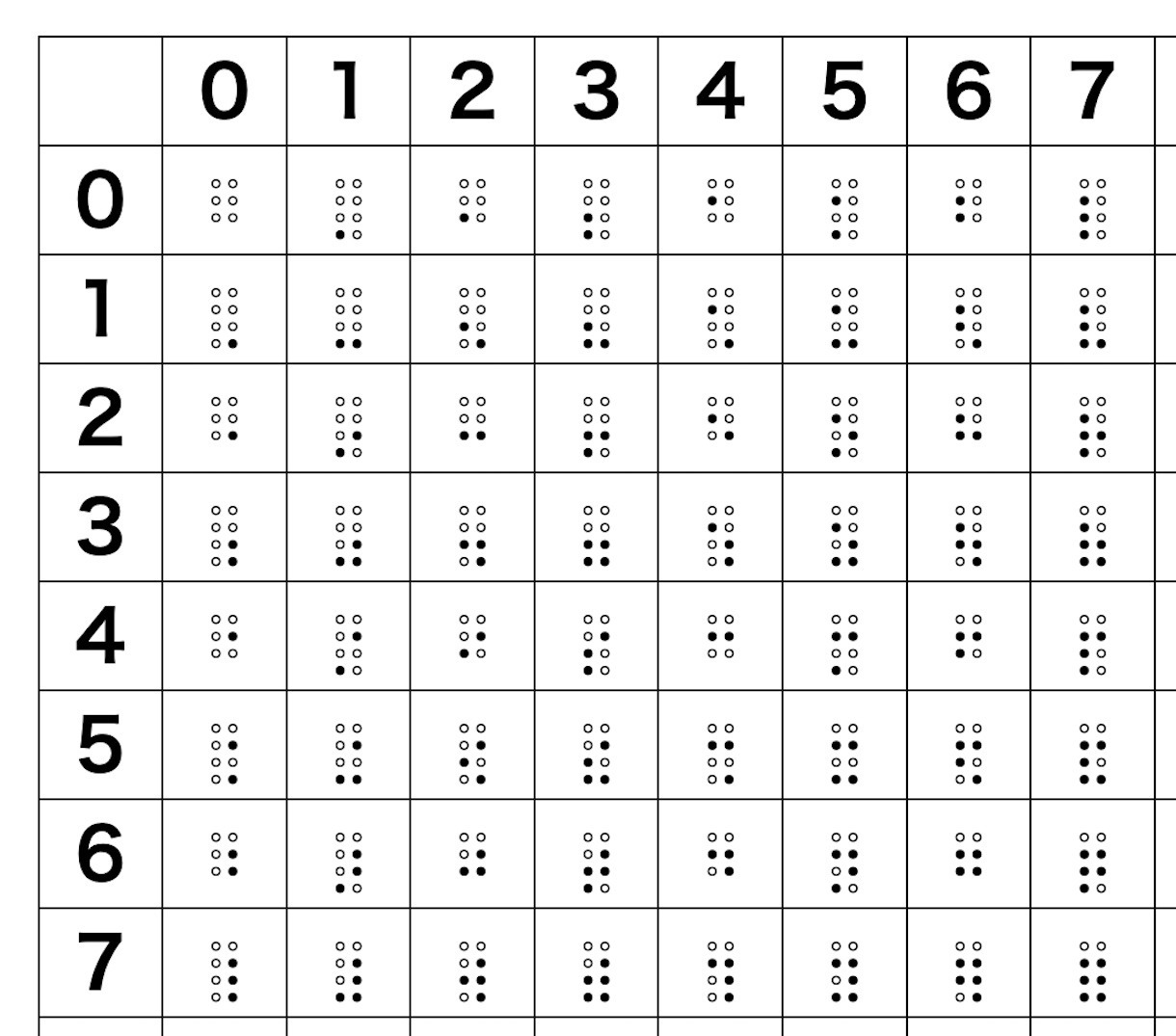
77までを拡大した表です。エンジニアには馴染み深い、二進法で読めますね!
6点の点字は下の空白を0と読むのがコツです。
128bitのUUIDを変換するとこんな感じです。
↓
⡭⡲⡉⣢⠸⡊⡎⢟⢙⣀⡜⢀⠧⡛⢉⠽
フォントによってかなり短くなってうれしいですね。



{kind=link}
{kind=link}
{kind=link}