 AI、機械学習を応用したステキなオープンソースライブラリ「
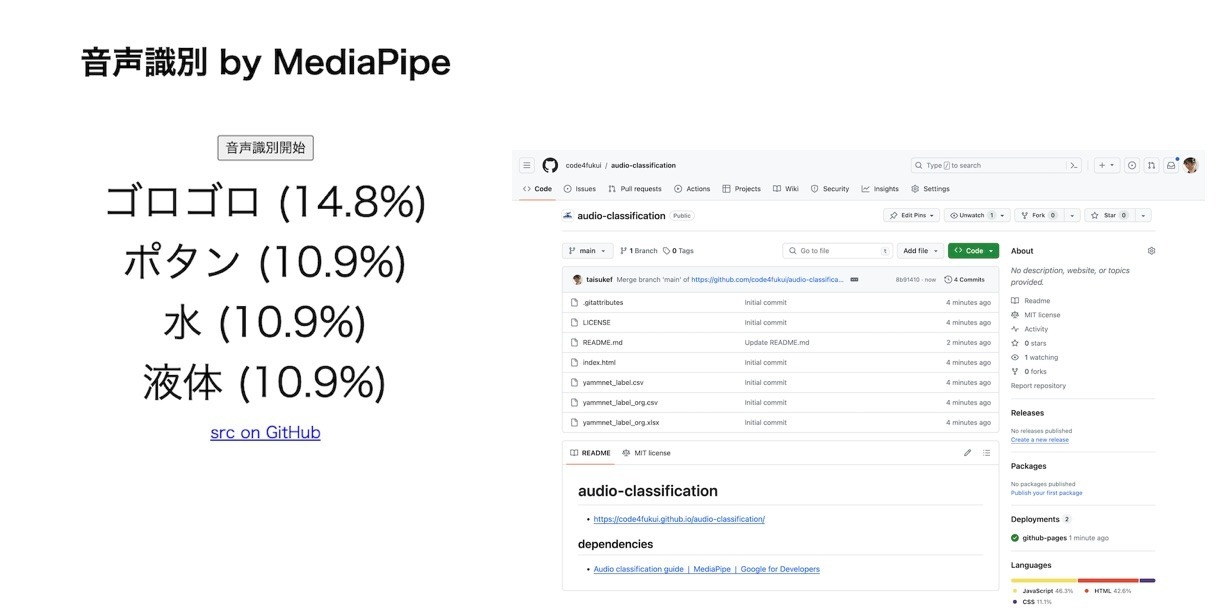
AI、機械学習を応用したステキなオープンソースライブラリ「ただ、音声名の記述が英語なのでよくわからないので、YAMNet audio classifierを日本語訳したものを用意して、日本語で表示するようにしたデモを作成しました。

「音声識別 by MediaPipe」
わかりやすくなりました!
「audio-classification on GitHub」
TensorFlow.jsで作られたESモジュールをインポートしているのでデモのプログラムはとってもシンプル!
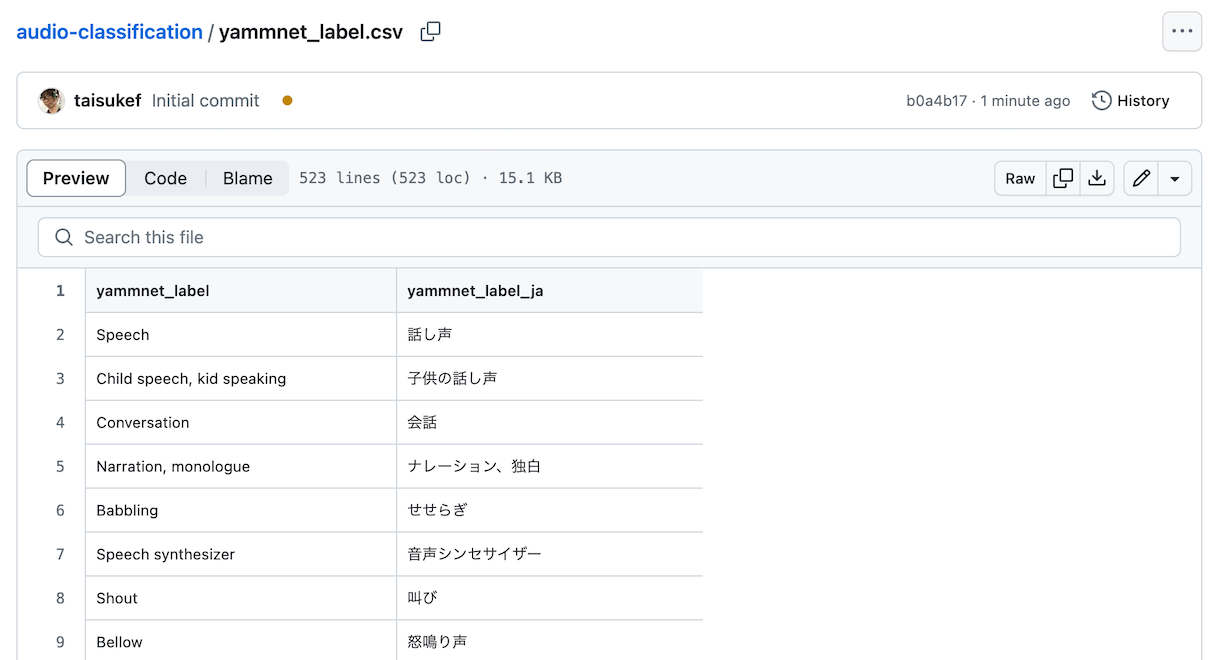
「audio-classification/yammnet_label.csv at main · code4fukui/audio-classification」
変なものは直したつもりですが、もっと良い訳があればコメントまたはプルリクをお送りください。
オープンデータなのでご自由に活用ください。
シチュエーション毎に発生しうる音のみに絞って識別させるなどで精度は上げられるでしょう。
Let's create with AI!



{kind=link}
{kind=link}
{kind=link}